- Iniciar el equipo con nuestra distro Linux predilecta.
- Montar el disco (Windows) de nuestra maquina.
- Acceder a la ruta Windows\System32
- Renombrar "Magnify.exe" por "Magnify.exe.bak".
- Copiar y pegar "cmd.exe"
- renombrar el archivo copiado como Magnify.exe
- Reiniciar el equipo y arrancar por windows.
- Al llegar a la pantalla de inicio presionar el botón "Accesibilidad".
- En el menu que se apertura seleccionamos la "Lupa", lo cual nos cargara en realidad una consola con privilegios admin
- Una vez allí listamos los usuario del sistema (net users)
- Para cambiar la cuenta del usuario simplemente ejecutamos net users usuarioACambiar
- Si cambiamos la cuenta de admin debemos habilitarla (no viene por defecto), para ello ejecutamos net users administrador /active:yes
- Reiniciamos nuevamente (vamos es tipico en la ventanita).
- Ya esta listo !!!

viernes, 14 de diciembre de 2012
"Recuperar" contraseña en Windows
Si, claramente el titulo puede verse extraño en un blog dedicado a hablar sobre linux, pero ya que todo se basa en la explotación de un error de Microsoft mediante el uso de una distro Linux no me parecio una mala idea publicarlo aqui. Dicho esto vamos a la materia:
jueves, 13 de diciembre de 2012
Busquedas PRO en Google o Google Hacking.
En la actualidad, no se encuentra para nada difundido el tema del correcto uso de los buscadores en internet. Para la mayoria de las personas, el buscador es mas una especie de Gúru que todo lo sabe al cual se le hacen preguntas como si fuera un humano... ( :-/ ¿¿??)
La verdad (en mi opinión personal), nada esta mas alejado de la realidad, y realizar busquedas partiendo de colocar preguntas en el buscador puede no ser la mejor manera de hallar información sobre un tema en la red; pero entonces, cuales son las mejores practicas a la hora de emplear Google ¿¿ :-/ ?? ...
Recomendaciones Basicas:
Las siguientes recomendaciones son extraídas de las ayudas básicas para las búsquedas de Google (aquí), pero me he permitido realizar algunos cambios...
- No te compliques: no es mala idea iniciar buscando el termino o sujeto del tema especifico.
- Añade palabras relevantes: de esta manera lograras resultados mas específicos, incluye términos que puedan asociarse directamente a lo que deseas encontrar.
- Busca pensando en como escribiría un autor: si estas buscando ayuda por un dolor de cabeza, escribir simplemente "Me duele la cabeza", puede no producir resultados útiles que te brinden soluciones al mal que te aqueja, por el contrario puede ser una mejor practica buscar algo como "Dolor de Cabeza Remedios" u otros términos similares (mas adelante les compartiré como hacer que el buscador se encargue de usar sinónimos a ciertos términos).
- Usa solo palabras importantes en lugar de frases o preguntas completas: el ejemplo de google va genial, en lugar de "país en el que los murciélagos son un augurio de mala suerte", viene mejor " murciélagos mala suerte".
Vistos los conceptos básicos sobre búsquedas, llega el momento de profundizar un poco mas, por lo que ahora vamos a ver como limitar nuestras búsquedas un poco mas. Igual que el caso anterior, estos primeros detalles vienen directo desde Google (aquí).
| Buscar una palabra o una frase exactas
"consulta de búsqueda" |
Utiliza comillas para buscar una palabra o un conjunto de palabras
exactas en un orden concreto sin aplicar las mejoras habituales, como la
corrección ortográfica o la búsqueda de sinónimos. Esta opción resulta
útil si buscas la letra de una canción o una cita de una obra literaria.
[ "chiquitita dime por qué" ] Sugerencia: utiliza las comillas solo si estás buscando una palabra o una frase muy concreta, ya que podrían excluirse resultados útiles por error. |
| Excluir una palabra
-consulta | Añade un guión (-) delante de una
palabra para excluir todos los resultados que incluyan dicha palabra.
Esto resulta especialmente útil en el caso de sinónimos como Jaguar la
marca de coche y jaguar el animal.
[ velocidad del jaguar -coche ] Sugerencia: también puedes excluir resultados con otros operadores. Por ejemplo, puedes excluir todos los resultados de un sitio en particular. [ pandas -site:wikipedia.org ] |
| Incluir palabras similares
~consulta | Normalmente, algunas palabras de la
consulta original se pueden sustituir por sinónimos. Añade el signo de
tilde (~) inmediatamente delante de una palabra para buscar esa palabra y
otros sinónimos.
[ información ~alimentaria ] incluye los resultados de "información nutricional". |
| Limitar la búsqueda a un sitio o dominio
site: consulta | El operador "site:" permite buscar
información en un mismo sitio web como, por ejemplo, todas las veces que
se menciona la palabra "Olimpiadas" en el sitio web de The New York
Times.
[ Olimpiadas site:nytimes.com ] Sugerencia: también puedes buscar en un determinado dominio de nivel superior como .org, .edu o en un dominio de nivel superior de país como .es o .de. [ Olimpiadas site:.es ] |
| Incluir un comodín
consulta * consulta | Utiliza un asterisco (*) en
una consulta como marcador de posición para cualquier término "comodín"
desconocido. Combínalo con el uso de comillas para buscar variaciones de
esta frase exacta o para recordar palabras en medio de una frase.
[ "quien siembra * recoge *" ] |
| Buscar al menos una de las palabras de la consulta
consulta OR consulta | Si quieres buscar páginas que
incluyan al menos una de varias palabras, incluye OR (en mayúsculas)
entre las palabras. Si no se incluyera OR, normalmente los resultados
mostrarían solo páginas que coincidan con ambos términos. También puedes utilizar el símbolo | entre las palabras para causar el mismo efecto.
[ sede olimpiadas 2014 OR 2018 ] Sugerencia: incluye frases entre comillas para buscar al menos una de varias frases. [ "copa del mundo 2014" OR "olimpiadas 2014" ] |
| Buscar un intervalo de números
número..número | Separa números con dos puntos
(sin espacios) para obtener resultados que contengan los números
incluidos en un intervalo determinado de cosas como fechas, precios y
medidas.
[ cámara "50..100 euros" ] Sugerencia: utiliza solo un número con dos puntos para indicar un límite superior o un límite inferior. [ ganadores copa del mundo ..2000 ] |
Continuando, llega el momento de hacer referencia a los operadores, "los
buscadores los emplean para hacernos la vida mas sencilla"; estos
están allí para brindarnos resultados mucho mas específicos y viene de
madre conocerlos...
| Operador | Propósito | Combinable | Usado solo |
|---|---|---|---|
| intitle | Busca en el titulo | si | si |
| allintitle | Busca el titulo | no | si |
| inurl | Busca en la URL | si | si |
| allinurl | Busca la URL | no | si |
| filetype | Permite espeficicar el tipo de archivo que se desea | si | no |
| allintext | Busca en el texto solamente | No en realidad | si |
| site | Buscan en un sitio especifico | si | si |
| link | Busca enlaces a otras paginas | no | si |
| inanchor | Buscan en las Anclas | si | si |
| numrange |
Localiza un numero
|
si | si |
| daterange | Busca un rango de datos | si | no |
| author | Busca por autor | si | si |
| group | Busca el nombre del grupo | No en realidad | si |
| insubject | Busca el asunto | si | si |
| msgid | Busca el msgid del grupo | no | si |
Pueden encontrar mas detalles en el articulo original en wikipedia -Ingles- (aquí).
Finalmente llega el momento de tratar el punto que posiblemente sea lo que llame la atención a muchos... Google hacking !!!. Primero que nada en este sentido debo advertir que no se trata de nada ilegal (aunque lo que hagan con los resultados si puede traer problemas y va bajo su propio riesgo y responsabilidad), lo que vamos a hacer es hacer busquedas especificas sobre elementos que los sysadmin no han debido dejar al descubierto o no han de haber permitido que se indexe por google.
Formalmente hablando, el google hacking se describe como (extraído de Taringa ):
"... consiste en explotar la gran capacidad de almacenamiento de información de Google, buscando información específica que ha sido añadida a las bases de datos del buscador. Si las búsquedas las orientamos a ciertas palabras clave que nos ayuden a encontrar información sensible, puntos de entrada sensibles a posibles ataques, como por ejemplo, este o cualquier otro tipo de información que tuviera carácter de sensibilidad, estaremos ejecutando un Google hack. Resumiendo: Google Hacking es buscar en Google información sensible ..."
Ahora, antes de poder hacer cualquier hacking es necesario conocer la forma en la que funciona google, para ello vamos a usar como base la explicación de segu-info.com.ar (para que reinventar la rueda no ??).
" Google no es más que un gran procesador de comandos y mientras mejor sea la combinación que usemos, mejores serán los resultados obtenidos. Como todos sabemos si colocamos una palabra en el cuadro de texto, Google entenderá que debe realizar la búsqueda de esa palabra. Pero si colocamos: (e^(i * pi)) + 1 entonces Google entenderá que deseamos realizar una operación matemática (la entidad de Euler, la fórmula más importante del mundo) y nos dará el resultado de la misma que es 0 (cero) en este caso.
Este buscador, basa su gran potencia en el algoritmo que utiliza; este se basa en complejas funciones matemáticas -mejoradas día a día- , que tienen como objetivo obtener la posición que cada página debe ocupar en el ranking.
Esta posición - PageRank- se logra mediante una valoración objetiva de la importancia de la
página web a buscar; El resultado es un
número de 0 a 10 que arrojado luego de aplicar una ecuación matemática compuesta por
más de 500 millones de variables y 3.000 millones de términos.
El algoritmo en cuestión, se aplica a las paginas indexadas y para esta tarea -indexación-, Google dispone de robots llamados Googlebots que se encargan de
almacenar cada sitio web e indexarlo en las bases de datos. Es decir que nuestro amigo
funciona como un inmenso repositorio de nuestras webs.
En la imagen puede verse la última vez que
el robots de Google ha revisado Segu-Info, la cantidad de páginas indexadas y la cantidad de
MegaBytes de información almacenados en su base de datos.
Esta base tiene dos objetivos:
- realizar las búsquedas sobre ella para evitar la búsqueda en los sitios reales, con la pérdida de performance asociada.
- permitir visualizar las páginas que ya no están online pero han sido indexadas en alguna oportunidad. Esta funcionalidad recibe el nombre de caché. ".
Dicho esto, al grano...
En la actualidad es posible encontrar un gran numero de post, artículos, E-books, libros y demás sobre el tema; por lo cual lo que aquí veremos debe ser considerado solo como un pequeño abre boca.
En cada uno de los casos descritos, emplearemos los consejos, filtros y operadores descritos al inicio:
1.) Localizar archivos que no deberían estar públicos:
En la actualidad es posible encontrar un gran numero de post, artículos, E-books, libros y demás sobre el tema; por lo cual lo que aquí veremos debe ser considerado solo como un pequeño abre boca.
En cada uno de los casos descritos, emplearemos los consejos, filtros y operadores descritos al inicio:
1.) Localizar archivos que no deberían estar públicos:
a.) Correos: filetype:pst inurl:[siente libre de probar], filetype:mbx mbx intext:Subject
b.) Logs de aplicaciones: +htpasswd +WS_FTP.LOG filetype:log
c.) Archivos con contraseñas o confidenciales:
*) filetype:bak createobject sa (Lineas de conexión ADODB)
2.)Localizar archivos en la cache:
a.) Errores de aplicaciones: "ORA-00936: missing expression"
3.)Localizar configuraciones por defecto:
a.) De apache: intitle:"Test Page for Apache" "It Worked!"
b.) De IIS: intitle:"Welcome to IIS"
4.)Localizar Errores de Configuración:
4.)Localizar Errores de Configuración:
a.) Búsqueda de vulnerabilidades: "VNC Desktop" inurl:5800
Finalmente, hora de nuevamente hacer la aclaración, estas búsquedas no son ilegales, pero puede meternos en problemas lo que hagamos luego con los conocimientos y resultados obtenidos...
"Con un gran poder viene una gran responsabilidad"
viernes, 30 de noviembre de 2012
Como saber el número de HBA's en un equipo
Por cosas de trabajo (si, para no perder la costumbre), me he visto en la necesidad de conocer el numero de HBA's conectadas a un equipo, y ya que me ha tomado algo de tiempo la búsqueda, he decidido centralizar las alternativas encontradas para ello, luego de mucho probar he encontrado las siguientes alternativas:
- # lspci | grep -i fibre
- ls /sys/class/fc_host/
- cat /proc/scsi/[driver]/ hierarchy
jueves, 20 de septiembre de 2012
Proxy en Yum
Ya hace mucho tiempo escribi un articulo sobre como indicar a aptitude que se encontraba tras de un proxy, en esta oportunidad; voy a hablar sobre como indicarle a yum que se encuentra tras un proxy y mas aun indicarle los parametros de Autentificación a Yum
El Escenario:
Tenemos un equipo con una distro .RPM que se encuentra tras un proxy que emplea autentificación.
Como Proceder:
Lo que debemos es habilitar el proxy en Yum e indicarle los parametros de autentificación y esto lo hacemos simplemente editando el archivo de configuración de yum, el /etc/yum.conf
Básicamente lo que haremos será editar el archivo /etc/yum.conf y definir los parámetros proxy, proxy_username y proxy_password indicandole los valores del proxy, el usuario y su password:
# The proxy server - proxy server port number
proxy=http://vsnlproxy.iitk.ac.in:3128/
# The account details for yum connections
proxy_username=spsingh
proxy_password=password
proxy=http://vsnlproxy.iitk.ac.in:3128/
# The account details for yum connections
proxy_username=spsingh
proxy_password=password
Ya definidos estos parámetros simplemente guardamos, cerramos y probamos ejecutando yum.
martes, 18 de septiembre de 2012
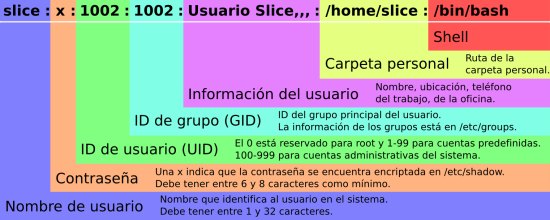
Chuleta /etc/shadow
El archivo /etc/shadow almacena información sobre las contraseñas cifradas de los usuarios de nuestro sistema, al igual que el /etc/passwd, es una archivo de lista (los ":" son el separador de columnas), cuya estructura es:

Chuleta /etc/passwd
El archivo /etc/passwd es el que contiene la información de identificación de los usuarios del sistema. Este es una lista de atributos separados por dos puntos (:) cuya estructura les dejo a continuación:
martes, 11 de septiembre de 2012
Cambiar nombre host
Como muchas de las cosas en mi blog, son las necesidades del trabajo las que me llevan a escribir (a fin y al cabo estas son mis notas personales), en cualquier caso, la entrada de hoy esta dedicada al cambio del nombre del Host.
El procedimiento que ahora describo esta probado en RHEL, aunque debería funcionar igual en otras distribuciones...
El procedimiento que ahora describo esta probado en RHEL, aunque debería funcionar igual en otras distribuciones...
- Editar el archivo network (/etc/sysconfig/network) y cambiar el nombre del host en la variable
- Editamos el archivo /etc/hosts agregando la info del equipo (
192.168.0.1 nombre). - Cambiamos el nombre del host usando el comando hostname.
hostname redhat9- Ejecutar nuevamente el comando hostname sin incluir el host para ver el cambio.
- Finalmente reiniciar el servicio de red para aplicar los cambios realizados (s
ervice network restart). - Para verificar que el nombre del host fue realmente cambiado debemos salir e ingresar nuevamente a la sesión.
viernes, 7 de septiembre de 2012
remontar fichero de solo lectura
Producto del día a día en el trabajo, y haciendo una de esas actividades que se hacen repetitivas (y con los ojos cerrados), sin querer agrege un dispositivo al /etc/fstab y expecifique mal su UUID. Este echo, junto el pequeño problema del punto de montaje de este dispositivo hizo que al reiniciar el equipo mi sistema reportara un error y me dejara en una consola.
Al principio pense que todo seria sencillo, corria un blkid, revisaba el UUID y luego entraba al /etc/fstab y solucionaba el error; pero la realidad fue otra, ya que al intentar solucionar el error me encontre con que el sistema (/) se había montado solo lectura....
Al principio pensé forzar la escritura o cambiar permisos, pero no funciono, entonces vi la luz:
# mount -o rw,remount /dev/sdaX
De esta forma se pide que se monte (o remonte) el dispositivo /dev/sdaX como lectura y escritura.
martes, 4 de septiembre de 2012
Saludo Consola Grafica
Desde que lo vi en Iron man II, he estado con la cosa de modificar el comportamiento de mis consolas obligándolas a mostrar un mensaje personalizado al momento de llamarlas, al fin he tenido un poco de tiempo para realizar esto y mas aun para publicar como se hace.
En realidad, esto es algo muy sencillo de hacer, lo que debemos simplemente es editar los detalles de nuestro perfil, para ello modificamos el archivo "bashrc" que se encuentra en nuestro home (ojo es un archivo oculto -inicia en punto ".")
Personalizando el saludo para nuestro usuario:
- Editamos el archivo bashrc de nuestro usuario ingresando a la ruta /home/bashrc
- Agregamos al final el mensaje que queremos que aparezca:

- Cerramos y lanzamos una nueva consola para ver los resultados:

Personalizando para Root:
De similar manera podemos proceder para el saludo de root, solo que en este caso, el archivo se encuentra en /root/.bashrc.

Definiendo un Alias:
Finalmente, para terminar este tema, es importante comentar los "alias", esto hablando en criollo son nicks que podemos definir para la lista de comandos que mas usamos, y para ello simplemente debemos agregar una linea como la que sigue el el .bashrc del usuario:echo 'alias imagenes="cd /media/discoduro/archivos/Pictures"' >> ~/.bashrc && . ~/.bashrc La ultima parte de este comando simplemente lo que hace es regargar el bash.
Si queremos verificar que todo ha salido bien, simplemente ejecutamos el alias o tecleamos:
alias
para ver la lista de nicks definidos.
ssh sin contraseña
Muchas veces en el día a día de un sysadmin, nos es necesario automatizar tareas las cuales implican conexiones remotas, estas situaciones ponen al administrador ante la necesidad de poder hacer login remoto sin tener que el mismo escribir la contraseña de autentificación.
Para solucionar esta necesidad, existe el metodo de autentificación por llaves en el protocolo ssh, el cual permite evitar la necesidad de teclear la contraseña al establecer conexión con los host.
Habilitar este comportamiento es muy sencillo, simplemente es necesario realizar lo siguiente:
Generar las llaves de ssh:
- Para ello ejecutamos: # ssh-keygen -t dsa:

Transferir la llave publicas al remoto:
- Nos valdremos en este caso de la utilidad "ssh-copy-id" :

Probar la conexión:
- Realizamos una conexión con el usuario y el host especificado en el paso anterior:
ssh usuario@equipo
Cinnamon en Fedora 17 (RHEL)
 Cinnamon:
Cinnamon:
Tal como leemos en wikipedia: "Cinnamon es una bifurcación de GNOME Shell, desarrollado inicialmente por Linux Mint. Intenta proveer un entorno de escritorio más tradicional basado en la metáfora de escritorio, como GNOME 2. Cinnamon usa Muffin, una bifurcación del gestor de ventanas de GNOME 3 Mutter, como su gestor de ventanas".
Para mucho de nosotros, este entorno nos ofrece mucho de lo bueno del nuevo Gnome 3, pero desde una interfaz mas acorde con lo que estamos acostumbrados.
Actualmente, cinnamon no se encuentra en los repositorios de Fedora, pero podemos agregar un nuevo repo e instalar desde allí, para ello ejecutamos:
# curl http://repos.fedorapeople.org/repos/leigh123linux/cinnamon/fedora-cinnamon.repo -o /etc/yum.repos.d/fedora-cinnamon.repo
Con lo anterior nos bajaremos e instalaremos un nuevo repo a la lista de nuestro yum, ahora como es costumbre es necesario ejecutar un update para poder ver la lista de paquetes que este nos ofrezca, para ello ejecutamos:
# yum check-update
Una vez terminado el proceso de update (puede ser mas o menos rápido dependiendo de nuestra conexión y otras variables), es necesario instalar el paquete de cinnamo; bastará simplemente con ejecutar:
# yum install cinnamon
Terminada la instalación simplemente debemos cerrar la sesión actual y logearnos nuevamente, recordando seleccionar Cinnamon como entorno de escritorio.
Grub-customizer (RHEL)
 En esta oportunidad, vamos a ver una nueva alternativa para jugar con la configuración de nuestro Grub... Esa pantalla que sin duda alguna se convierte en la primera impresión de nuestro sistema ante los demas y que puede decir mucho de nuestros equipos.
En esta oportunidad, vamos a ver una nueva alternativa para jugar con la configuración de nuestro Grub... Esa pantalla que sin duda alguna se convierte en la primera impresión de nuestro sistema ante los demas y que puede decir mucho de nuestros equipos.
Si, en general modificar el grub es muy sencillo, es cosa simplemente de editar un archivo y listo !!!, ok, es verdad pero para aquellos que no quieren introducirse en ese mundo y prefieren una gui que les ayude, aquí encontrarán una gran aplicación.
Grub-customizer:
Lo que debemos hacer, es simplemente instalar la fuente, lo malo es que por ahora no se encuentra en los repositorios de distros RPM's, por lo que simplemente debemos ingresar a la Web del proyecto y bajarnos el rpm:
Una vez descargado, la cosa es simplemente instalarlo, para ello nos movemos al directorio donde lo bajamos y le damos doble click...
Luego de instalado, podemos ejecutarlo con el comando grub-customizer.
MS Sql en RHEL
Por motivos de trabajo, he tenido al fin la necesidad de conectar desde Linux con una base de datos de MS-Sql y como siempre paso por aca para dejar la receta de como hacerlo. El proceso es bien sencillo y simplemente es necesario bajarnos un par de paquetes, realizar la configuración y listo, ya tendremos nuestra conexión operativa.
El escenario al que aplica este articulo es uno en el que tienes una aplicación que requiere conectarse a un segundo equipo donde se ejecuta el MS-Sql. Para el caso especifico, tenemos un equipo con una aplicación desarrollada en php, el cual ya tiene instalado el servidor apache y el php.
En cualquier caso, y esto sobre todo para aquellos que quieran documentarse un poco mas, es esta solución vamos a emplear la biblioteca Freetds (I,II) y el paquete php-mssql el cual nos permite hacer uso de las funciones Ms-Sql dentro de nuestro código php.
El proceso
Lo que debemos hacer primeramente es instalar los siguientes paquetes:
- Freetds,
- Php-mssql (o el equivalente para el lenguaje en el que tenemos el desarrollo).
# yum install freetds.arch php-mssql.arch
* donde arch hace referencia a la arquitectura de nuestra plataforma.
Luego de realizada la instalación de los paquetes es momento de realizar la configuración del TDS, para ello simplemente debemos modicar el archivo de configuración del tds e indicarle los parámetros de nuestro servidor.
- Accedemos al archivo /etc/freetds.conf
- Ubicamos la linea (A typical Microsoft server) y procedemos a modificarla.
- Agregamos los parametros de configuración en base a nuestro escenario asi:
[NombreServidor]
host = Dirección IP
port = puerto
tds version = VersiónDelTDS
Es muy importante, que los parámetros estén bien configurados dentro del archivo para que de esta forma nuestra aplicación se pueda conectar de manera correcta, en tal sentido, debemos incluso asegurarnos de tener correctamente seleccionado la versión del TDS (varia en base a la versión de MS-Sql que use nuestro server).
Dentro del /etc/freetds, también podemos habilitar el registro de log, el cual es muy útil a la hora de monitorear y de hacer diagnostico de errores, para ello simplemente debemos descomentar la opción de dump en el log.
Finalmente, podemos probrar que todo este bien ejecutando:
# tsql -S NombreServidor -p Puerto -U UsuarioBaseDatos
Esto nos debería permitir conectarnos al servidor especificado.
jueves, 31 de mayo de 2012
Sincronización de Carpetas entre Equipos con Rsync
En mi día a día, trabajo indistintamente con diferentes computadoras; cada una de ellas tiene un fin especifico, esto me ha sido muy útil en realidad, pero ha traído consigo la necesidad de tener la misma información en todos los equipos (si, de verdad necesito esa redundancia de datos).
La Solución a este problema ya la conozco desde hace tiempo, sincronizar los contenidos entre equipos.... Ahora, debo decir que por diversas situaciones (mas que todo falta de ponerme las pilas con esto), no la había implementado y mucho menos comentado aquí, pero ya ha llegado el momento...
Opción 1: La nube;
Esta posibilidad siempre me ha resultado muy interesante, sobre todo porque la mayoría de los servicios en la red cuentan con aplicaciones para dispositivos móviles y al tener yo un par de estos equipos (iPod Touch, SmartPhone Android) la solución va como anillo al dedo.
Las posibilidades son muchas y la verdad que es necesario que nos sentemos un buen rato a leer contratos de licencias, pros, contras, opiniones y review sobre este tema ya que de estos servicios siempre hay mucho que hablar. En cualquier caso, ir mas allá con los temas no es la idea de este post, así que solo me limitare a comentar un par de opciones:
- Gdrive: del servicio de almacenamiento en la red de Google mucho se hablo y durante un buen tiempo, las especulaciones sobre la propiedad de los archivos que allí se suban y otros temas mas dan polémica a la elección, pero su integración con los demás servicios han restado importancia a esto. El servicio es muy competitivo al ofrecer 5 Gb, pero al ser nuevo cuenta con aplicaciones para solo algunas plataformas.
- Dropbox: muy conocido en el mundo del almacenamiento en la nube, de este servicio mucho se ha hablado por la temática de sus políticas de seguridad, la forma en la que trata los archivos y en fin, otro montón de cosas, pero en cualquier caso cuenta con un muy envidiable numero de usuarios y app para casi todas las plataformas lo que lo hace una opción nada despreciable.
- owncloud: te gusta hacer las cosas por ti mismo y no depender de los demás..., crees que tu información es muy importante para dejarla en los servidores de otros..., tienes conocimientos, un buen proveedor de internet y la posibilidad de dejar tu equipo encendido y conectado 24/7; si alguno de esos es tu caso pues esta puede llegar a ser una opción para ti, pero documentate bien antes de hacer nada.
En mi caso, yo he instalado en mis equipos y dispositivos móviles la app de dropbox y por ese medio comparto alguna de mi información, no puedo negar en ningún momento su utilidad y beneficios, pero para mi necesidad esto es solo una solución a medias ya que el volumen de datos sobrepasa con creces lo ofrecido por dropbox, no pienso pagar por el servicio y tampoco me confió en colocar cosas importantes que he desarrollado allí (seguro mato a confianza -como dicen en mi país)...
Opción 2: Rsync;
Y en esta me quede.... rsync es una aplicación libre para sistemas de tipo Unix y Microsoft Windows que ofrece transmisión eficiente de datos incrementales, que opera también con datos comprimidos y cifrados.
Mediante una técnica de delta encoding, permite sincronizar archivos y directorios entre dos máquinas de una red o entre dos ubicaciones en una misma máquina, minimizando el volumen de datos transferidos.
Una característica importante de rsync no encontrada en la mayoría de programas o protocolos es que la copia toma lugar con sólo una transmisión en cada dirección. rsync puede copiar o mostrar directorios contenidos y copia de archivos, opcionalmente usando compresión y recursión.
Actuando como un daemon de servidor, rsync escucha por defecto el puerto TCP 873, sirviendo archivos en el protocolo nativo rsync o via un terminal remoto como RSH o SSH. En el último caso, el ejecutable del cliente rsync debe ser instalado en el host local y remoto.
rsync se distribuye bajo la licencia GNU General Public License.
Actuando como un daemon de servidor, rsync escucha por defecto el puerto TCP 873, sirviendo archivos en el protocolo nativo rsync o via un terminal remoto como RSH o SSH. En el último caso, el ejecutable del cliente rsync debe ser instalado en el host local y remoto.
rsync se distribuye bajo la licencia GNU General Public License.
Sincronizando con Rsync:
Caso 1, Sincronizando medios extraibles: En este ejemplo el directorio origen es /home/usuario y vamos a sincronizarlo con un directorio destino (/media/disco/copia_usuario ) que puede estar en otra partición del disco duro, o en otro disco duro externo, o en un pendrive de suficiente capacidad. Ejecutar en una terminal el comando siguiente:
rsync -avrz /home/usuario/ /media/disco/copia_usuario
Breve explicación de las opciones:
opción -a preserva las propiedades del fichero (permisos, timestamps…)
opción -v verbose (para poder ver lo que hace)
opción -r recursivo, para sincronizar los subdirectorios
opción -z, lo que activaría la compresión en destino.
opción –delete elimina en destino los ficheros que no están en el origen
Caso 2, Sincronizando entre equipos: En este otro ejemplo el directorio origen es /home/usuario y vamos a sincronizarlo con ese mismo directorio, pero en otro maquina (10.0.0.200/home/usuario) que puede estar en otra partición del disco duro, o en otro disco duro externo, o en un pendrive de suficiente capacidad. Ejecutar en una terminal el comando siguiente:
rsync -avrz /home/usuario/ 10.0.0.200:/home/usuario
rsync -avrz /home/usuario/ 10.0.0.200:/home/usuario
En cualquier caso, es posible que creemos una serie de scripts que nos hagan la tarea mucho mas sencilla y automatizada, pero de ello hablare en un próximo post... (aun debo hacer los scripts y probarlos).
Grsync:
Esta aplicación hecha en Perl, se puede usar para sincronizar desde el entorno grafico. Puede ser utilizado eficazmente para sincronizar directorios locales y remotos. Por ejemplo, algunas personas usan grsync para sincronizar su colección de música con un dispositivo extraible o una copia de seguridad de archivos personales a una unidad de red.
Tiene una única “ventana”, en la que se selecciona el nombre de la sesión, la carpeta de origen (la que se va a copiar/sincronizar) y la carpeta de destino (con la que se va a sincronizar)

miércoles, 30 de mayo de 2012
Virtual box en LMDE
Ya anteriormente he tocado el tema de virtual Box, en realidad, este soft siempre ha sido una constante en mis instalaciones, ya que por razones muy diversas siempre lo he visto muy útil para el trabajo...
En cualquier caso y mas alla de hablar de polémicas sobre el soft, su licencia, su uso, pros y contras ahora me referiré a como instalarlo en nuestras maquinas con LMDE....
Repositorios:
La gente de Oracle, cuenta con un repositorio el cual podemos agregar a nuestro /etc/ap/sources.list y desde allí instalar. En cualquier caso, esto no es obligatorio, ya que el paquete también se encuentra disponible en los repos de Mint...
El repo de VirtualBox es:
De esta forma el proceso se limita a ejecutar:
# aptitude install virtualbox
Descarga HTTP:
De igual manera, es posible descargar via http, para ello simplemente es necesario ir a https://www.virtualbox.org/wiki/Downloads y seleccionar la descarga que deseamos hacer.
De este modo tendremos un .deb, el cual podremos instalar con la ayuda de Gdebi (aplicacion que viene por defecto en mint).
Motores de Busqueda Firefox -LMDE-
Una de las primeras sorpresa con Mint Debian Edition (LMDE), fue que por default, no te trae a Google como motor de búsqueda en Firefox... Al principio me pareció sumamente extraño, puesto que suele ser el defecto en la mayoría de las distros, pero luego de pensar un poco me di cuenta que no es una mala decisión, a fin de cuentas -sin darnos cuenta- estamos alimentando ese gran monstruo llamado Google con montones de datos, nuestros, gustos, pensamientos y demás....
En fin, dejando de lado todo ese proceso de análisis (que es necesario pero no el objeto de este post), la idea es comentar la instalación de motores de Búsqueda para firefox en LMDE... Así la cosa, vamos al grano:
Motor de Busqueda en Firefox
 Cuando hablamos del motor de Busqueda, nos referimos a la casilla que sigue el área de Dirección dentro del navegador, su utilidad basica es la de permitir introducir "Querys" de busqueda que serán procesados por el motor que hallamos seleccionado, esto, básicamente permite ahorrar algo de tiempo....
Cuando hablamos del motor de Busqueda, nos referimos a la casilla que sigue el área de Dirección dentro del navegador, su utilidad basica es la de permitir introducir "Querys" de busqueda que serán procesados por el motor que hallamos seleccionado, esto, básicamente permite ahorrar algo de tiempo....
En la actualidad, la batalla por ocupa ese lugar es mas que interesantes y las posibilidades son bastante amplias, lugares como wikipedia, Mercadolibre tienen sus propios add para ser instalados en los navegadores.
Manipulando el motor
Para manipular los diversos motores, el proceso es bien sencillo, simplemente debemos en la caja de motor, hacer click en la Flecha luego del icono del motor y seleccionar "Administrar Motores de Busqueda" en el menú desplegable, esto nos abrirá una ventana como la siguiente:

Desde aca podremos:
- Organizar el orden de nuestros motores,
- Instalar nuevos motores "Obtener más motores de búsqueda..."
- Eliminar Motores de búsqueda,
- Etc.
Instalando Google como motor de Búsqueda:
Sencillo,
- desde la ventana anterior, seleccionamos "Obtener más motores de búsqueda...",
- Esto nos dirigira a la pagina www.linuxmint.com/searchengines/ desde la cual podremos elegir a google (y a otros mas).
Debo indicar, que este de esta forma, instalamos los motores que provee el proyecto Mint, ahora si queremos ver todos los soportados por firefox podemos visitar https://addons.mozilla.org/es-es/firefox/search-tools/ la diferencia en cuanto a cantidad es astronomica; incluso pueden desarrollar el suyo propio si se animan....
Linux Mint -Debian- (LMDE - Instalación)
Producto de una metida de pata hace unos días, y motivado en muy buena parte por el tema de hallar un entorno de escritorio bueno gráficamente bonito y configurable también, me he decidido migrar a Linux Mint Edición Debian....
El review técnico del porque de la elección, los pros, los contras y mi opinión luego de la prueba lo dejo para una próxima entrada, por ahora voy a comentar el proceso de instalación.
Instalando Mint -LMDE-
- Luego de iniciar el Mint en Live, simplemente click en la Opción de instalar que tenemos en el escritorio

- Posteriormente, seleccionamos el idioma

- Seleccionamos nuestra "Timezone"

- Seleccionamos el Modelo, la distribución y la Variante para nuestro teclado

- Definimos el disco donde se realizará la instalación

- Particionamos

- Definimos Usuarios y contraseñas

- Indicamos donde se instalara el Grub

- Listo, ahora se nos presenta el resumen... Si todo esta bien vamos a instalar...

- Dejamos que el proceso termine (se supone dura unos 10 minutos)


miércoles, 23 de mayo de 2012
Instalar ultimas versiones de Firefox en Debian
Como parte de la políticas de trabajo en Debian, los paquetes deben pasar un largo proceso para poder llegar a la distribución. Esta política, aunque es la base para proporcionar mayor estabilidad también trae consigo que en las versiones estables no se cuente con las ultimas versiones de software.
Es por esta situación, que hoy pongo por este medio las notas de como instalar las ultimas versiones de Firefox en nuestro sistema....
Es por esta situación, que hoy pongo por este medio las notas de como instalar las ultimas versiones de Firefox en nuestro sistema....
Al Punto...
- Primero que nada, si tenemos una versión anterior de Firefox o Iceweasel instalado debemos desintalarlo:
# aptitude purge firefox iceweasel
- Posteriormente, debemos hacer es descargar Firefox, para ello vamos a la página de proyecto.
- Una vez descargada la fuente, la descomprimimos (cualquier método es valido).
- Del paso anterior, se crea una carpeta llamada "firefox", ahora debemos copiar esa carpeta en /usr/lib par ello ejecutamos:
cp -rv /home/usuario/Escritorio/firefox /usr/lib/
- Crearemos ahora un enlace simbólico del archivo que ejecuta firefox con el comando:
ln -s /usr/lib/firefox/firefox /usr/bin/firefox
Creando un Lanzador:
Seguramente para finalizar nos gustaría agregar un lanzador a la aplicación, bueno para ello simplemente debemos de:
- Botón derecho sobre el icono de "aplicaciones" y click en "Editar menús"
- Click en Internet y clic en +Elemento nuevo
- Rellenamos el cuadro:
Tipo: Aplicacion
Nombre: Firefox 12
- En el text de "Comando", click en "Examinar" y buscamos el archivo "Firefox" en /usr/bin
- Click en "Aceptar"
- Listo, ya se puede ejecutar Firefox desde "aplicaciones" "internet" !!
martes, 22 de mayo de 2012
Cambiar contraseña Root en Mysql
Para muchos puede resultar una trivialidad, pero para otros viene muy bien conocer como realizar este proceso, que aunque para algunos es el pan nuestro de cada día en la Administración de Bases de datos para otros es un vació.
Olvido:
En el proceso que describo a continuación, parto del supuesto de que se tiene Mysql con contraseña y esta se ha olvidado (:S), para recuperarla (cambiarla) procedemos así:
- Primero debemos detener el servicio del servidor MySQL
# service mysqld stop ó /etc/init.d/mysql stop
- Ahora debemos iniciar nuevamente el servicio pero impidiendo que se carguen los permisos en las tablas para poder modificarlas libremente, ósea en pocas palabras tenemos acceso ilimitado a todas las tablas de MySQL.
# mysqld_safe --skip-grant-tables
- Alternativamente si queremos evitar accesos desde la red (por seguridad) también denegamos las conexiones entrantes TCP/IP, para mantener el “full acceso” solamente como entorno local.
# mysqld_safe --skip-grant-tables --skip-networking&
- El siguiente paso es ingresar a la consola de MySQL
$ mysql –u root
- El servicio MySQL no nos preguntara por la contraseña ya que hemos usado el parámetro –skip-grant-tables al iniciar el servicio nuevamente.
- Luego seleccionamos la base de datos del sistema
mysql> use mysql;
- Por ultimo actualizamos la nueva contraseña que deseamos colocarle al usuario root
mysql> UPDATE users set password=PASSWORD(‘nueva_contraseña’) WHERE user = ‘root’;
- Debemos ver una salida generada por MySQL similar a la siguiente
Query OK, 1 rows affected (0.05 sec)
Rows matched: 1 Changed: 1 Warnings: 0
- Salimos de la consola de MySQL
mysql> exit
- Reiniciamos el servicio MySQL
# service mysqld restart ó /etc/init.d/mysql restart
Modificar:
Alternativamente, si el anterior no fuera este el caso; es decir, si conocemos la contraseña y lo que queremos es cambiarla, simplemente debemos:
- Ingresar a la consala MySQL con el usuario y contraseña,
- Seleccionar la BD del sistema (mysql),
- Ejecutar el query de Update,
- Salir de la consola MySQL y reiniciar el servicio.
lunes, 21 de mayo de 2012
Aptitude Básico
Según la wiki del proyecto debian, aptitude es un fronted, basado en Ncurseuna para APT; el mitico gestor de paquetes de Debian. Dado que esta basado en texto se ejecuta en un terminal o CLI y tiene un sin numero de caracteristicas entre las que destaca la posibilidad de correr en modo Interactivo o en modo Manual.

A diferencia de APT, aptitude "No tiene poderes de super Vaca" lo que debería significar que no implemente la operación moo.... (Referencias aquí).
Sin embargo, es posible hallar un huevo de pascua si ejecutamos:
#aptitude moo -v
 #aptitude moo -vv
#aptitude moo -vv#aptitude moo -vvv
#aptitude moo -vvvv
#aptitude moo -vvvvv
#aptitude moo -vvvvvv
Uso interactivo:
Para ejecutar aptitude de forma interactiva lo único que debemos hacer es ingresar a una terminal e invocarlo, asi:
# aptitude
Algunas de las opciones dentro de la interfaz son:

- F10 para acceder al menu de uso de aptitude. Esta es la tecla principal.
- ? para ayuda
- 'arriba', 'abajo', 'izquierda', 'derecha' para navegar.
- 'Enter' para seleccionar.
- '+' o '-' para instalar/actilizar o remover un paquete.
- 'g' para previsualizar/confirmar aciones.
- 'q' para salir – esto tambien cierra cualquier ventana actual (‘g’ retroceder).
Uso Manual:
El uso manual es idéntico al de apt-get, como súper usuario ejecutamos:
# aptitude
Entre las acciones disponibles tenemos:
# aptitude update = Actualiza la lista de paquetes disponibles en los repositorios.
# aptitude safe-upgrade = Actualiza los paquetes que tengan disponibles nuevas versiones.
# aptitude full-upgrade = Actualiza paquetes, incluso si eso significa que debe desinstalar otros.
# aptitude search = Busca un paquete (aplicación) en los repositorios.
# aptitude show = Muestra información del paquete.
# aptitude install = Instala paquetes.
# aptitude purge = Elimina (desinstala) paquetes y sus archivos de configuración.
# aptitude remove = Elimina (desinstala) paquetes.
# aptitude clean = Elimina ficheros descargados de cuando se instaló software en el sistema.
# aptitude autoclean = Elimina paquetes deb obsoletos.
# aptitude hold = Fuerza a que un paquete permanezca en su versión actual, y no se actualice
Haciendo Upgrade de Versiones:
Es posible realizar 2 tipos de saltos, el primero es:
El salto de Versiones, este implica el cambio de una versión por una completamente nueva (p.e Lenny-->Squeeze). En este caso, el proceso debe realizarse en base a las release notes que se generan por arquitectura al momento de liberar una nueva Versión.
Es importante destacar, que las ultimas release notes (update lenny-->Squeeze) no recomiendan el uso de aptitude, en su defecto recomiendan el uso de apt-get... (Aquí).
El salto menor de Versiones, es un upgrade menor (p.e de lenny 5.0.1 a 5.0.2). Este proceso es mucho mas sencillo y lo podemos realizar simplemente ejecutando:
# aptitude safe-upgrade
viernes, 11 de mayo de 2012
Evitar la Modificación del /etc/resolv.conf
Tal como comente hace tiempo, en casa tengo instalado un equipo que hace las veces de servidor y que me permite compartir mi conexión a Internet, tanto por red cableada como por WiFi. Este equipo tiene instalado -entre otras cosas- bind9 y dhcp y se conecta a la red mediante un dispositivo PPP, el cual usa NetworkManager o Wvdial para realizar la conexión....
La cosa es que evidentemente, el archivo resolv.com (donde se indica la IP para la resolución DNS), esta configurado para mirar al LoopBack (127.0.0.1), pero se modifica con las DNS del proveedor cada vez que realizo el marcado y eso deja sin efecto en mi server la resolución de nombres de forma local.
Para evitar tal situación, he decidido modificar el archivo manualmente y posteriormente setear el atributo de Inmutabilidad en el, asi:
# chattr +i /etc/resolv.conf
# lsattr /etc/resolv.conf
Finalmente, si por alguna razón quiere desactivar el atributo, ejecuto:
# chattr -i /etc/resolv.conf
jueves, 3 de mayo de 2012
Network File System (NFS)
Instalación del Servidor y el Cliente NFS
Como siempre, vamos a la teoría y como siempre wikipedia:
 El Network File System (Sistema de archivos de red), o NFS, es un protocolo de nivel de aplicación, según el Modelo OSI. Es utilizado para sistemas de archivos distribuido en un entorno de red de computadoras de área local. Posibilita que distintos sistemas conectados a una misma red accedan a ficheros remotos como si se tratara de locales. Originalmente fue desarrollado en 1984 por Sun Microsystems, con el objetivo de que sea independiente de la máquina, el sistema operativo y el protocolo de transporte, esto fue posible gracias a que está implementado sobre los protocolos XDR (presentación) y ONC RPC (sesión) . El protocolo NFS está incluido por defecto en los Sistemas Operativos UNIX y la mayoría de distribuciones Linux.
El Network File System (Sistema de archivos de red), o NFS, es un protocolo de nivel de aplicación, según el Modelo OSI. Es utilizado para sistemas de archivos distribuido en un entorno de red de computadoras de área local. Posibilita que distintos sistemas conectados a una misma red accedan a ficheros remotos como si se tratara de locales. Originalmente fue desarrollado en 1984 por Sun Microsystems, con el objetivo de que sea independiente de la máquina, el sistema operativo y el protocolo de transporte, esto fue posible gracias a que está implementado sobre los protocolos XDR (presentación) y ONC RPC (sesión) . El protocolo NFS está incluido por defecto en los Sistemas Operativos UNIX y la mayoría de distribuciones Linux.
En palabras sencillas, NFS nos permite compartir una partición o dispositivo en nuestra red local, de esta manera podemos montarlo como si de una unidad mas se tratase en un cliente remoto, cosa que en muchos casos viene muy bien...
Características:
- El sistema NFS está dividido al menos en dos partes principales: un servidor y uno o más clientes. Los clientes acceden de forma remota a los datos que se encuentran almacenados en el servidor.
- Las estaciones de trabajo locales utilizan menos espacio de disco debido a que los datos se encuentran centralizados en un único lugar pero pueden ser accedidos y modificados por varios usuarios, de tal forma que no es necesario replicar la información.
- Los usuarios no necesitan disponer de un directorio “home” en cada una de las máquinas de la organización. Los directorios “home” pueden crearse en el servidor de NFS para posteriormente poder acceder a ellos desde cualquier máquina a través de la infraestructura de red.
- También se pueden compartir a través de la red dispositivos de almacenamiento como disqueteras, CD-ROM y unidades ZIP. Esto puede reducir la inversión en dichos dispositivos y mejorar el aprovechamiento del hardware existente en la organización.
Instalando:
Servidor:
En el servidor es importante tener instalado los servicios , para ello simplemente ejecutamos:
# aptitude install portmap nfs-server nfswatch
Posterior a la instalación, verificamos que los servicios están corriendo, para ello ejecutamos:
# rpcinfo -p
La salida de este comando debería lucir algo así:
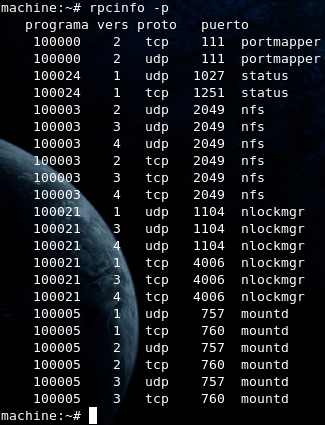
Clientes:
Del lado del cliente la cosa es mucho mas sencilla, solo debemos instalar nfs-common:
# aptitude install nfs-common
Configurando y Montando:
Exportando:
NFS va a exportar en la red todos los dispositivos o carpetas que se le indiquen en el /etc/exports, este es el archivo maestro de exportación y en el también podemos especificar detalles como con que maquinas vamos a exportar el dispositivo, que permisos daremos y así.
Obviamente, lo primero que debemos hacer es determinar las carpetas o dipositivos a ser exportados y posteriormente agregamos las lineas al /etc/exports basados en la siguiente estructura:
RutaACompartir IpsPermitidas/MascaraSubRed (Permisos)
Todo quedaría algo así:
Ahora para los cambios tengan efecto es necesario reiniciar el servicio:
# /etc/init.d//nfs-kernel-server restart
Montando en el cliente:
Aquí la cosa también es sencilla, pero tenemos dos opciones, podemos hacer que la partición se monte desde el arranque del sistema o podemos montar la carpeta o dispositivo cuando lo necesitemos.
Montado Permanente:
Si estamos seguros que el equipo cliente siempre va a poder conectarse con el servidor nfs desde el arranque siempre, esta es la mejor opción, para hacerlo simplemente hay que agregar un nuevo punto de montaje en el archivo /etc/fstab; el formato es:
IpServidor:/RutaCompartida /PuntoMontajeLocal TipoPartición Opciones Dump Pass
Nos quedaría algo así:
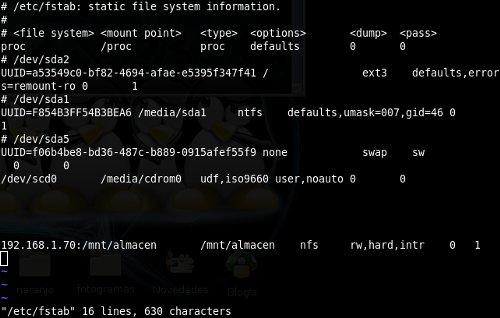
Hecho el cambio, lo que debemos hacer es remontar todos los puntos conocidos ejecutando:
# mount -a
Y listo, ya debemos tener nuestro sistema compartido accesible desde el cliente.
Comando de Montado:
Alternativamente, es posible que no queramos que el cliente monte el dispositivo o carpeta remoto desde el inicio, entonces la alternativa es indicarle el montaje de forma manual, para ello ejecutamos:
# mount -t nfs IpServidor:/RutaCompartida /PuntoMontajeLocal
Suscribirse a:
Comentarios (Atom)